
Elasticsearch 維運紀錄 - Troubleshooting

Elasticsearch 在日常維運中常常有需要透過 Kibana 提供的 RESTful API 來做一些叢集參數調整與處理。
不管是初始系統參數設定,或者是隨著業務成長,都必須盡可能使分散式方案的各個節點資料平均,才不會常常亮紅燈接電話。 接下來分享我目前有使用過的 API 以及情境:
除錯!遇到 ES RED Status 的第一步
遇到錯誤的狀態下,可以透過 explain 來看目前整組叢集正遇到什麼問題,同時可以使用 indices api 查看資料狀態
- GET /_cluster/allocation/explain
- GET /_cat/indices?v&s=health:desc
ES Snapshot 問題
如果問題發生在 Snapshot 卡住,或者資料無法透過 ES 自動還原成 GREEN 狀態,就會要試著從已有備份的 indices 做 restore 還原。
假設你有自動做 Snapshot 但遺失或者有時間誤差,如果選用 AWS ES 會自動幫你建立 Snapshot
可以參考 AWS ES cs-automated 自動幫你做的快照備份是否可以派上用場
For domains running Elasticsearch 5.3 and later, Amazon ES takes hourly automated snapshots and retains up to 336 of them for 14 days.
- GET /_cat/repositories?v # 查看你備份資料會放在哪個 Repository 內
- GET /_cat/snapshots/{{REPOSITORY}}/?v # 查看 Repository 內的資料備份狀況以及版本
- DELETE /{{INDEX_NAME_1}},{{INDEX_NAME_2}} # 要做 restore 前,一定要先砍掉舊(RED) 的 indices,該 API 可以使用
,分隔多個 indices - POST /_snapshot/{{REPOSITORY}}/{{SNAPSHOT_VERSION}}/_restore # 指定資料來源跟版本做復原
調整 ES Shard 數量 - Reindex
我遇過升級 ES 或者需要將現有的 Indices 做 Mapping 或者是 Shard 的調整,就需要透過 reindex 指令。
其中如果要調整 Indices 的 Shard 數量設定,必須透過 reindex 指令,無法直接異動正在使用的 Indices 喔!
如果要策略性的設定 Shard 數量,可以透過 create template 的功能來做設定配置
PUT /_template/{{name_you_want_to_be}}
{
"index_patterns": ["x-x-summary*", "x-summary*"],
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
POST /_reindex
{
"source": {
"index": "x-x-201901"
},
"dest": {
"index": "x-x-201901-"
}
}
調整 ES Replicas 數量
分散式節點通常會搭配 Replicas 避免資料遺失,可以針對各別的 Indics 做不同備份數量設定。如果異動 Replicas 設定可以在已經建立的 Indices 直接動工,而 Shards 是不行的,兩種差異提點。
- PUT /{{INDEX_NAME}}/_settings/
{
"index" : {
"number_of_replicas" : 1
}
}
ES 不穩定因素 - Shard 不平均
最後分享一下自己有遇到的 AWS ES 維運經驗,通常 ES 變成 RED Status 很有可能是整組叢集資料分配不平均,造成部分硬體負荷過大。
透過 Indices API 可以觀察目前設定是否洽當,如圖,比如說觀察 Shard(pri) 切成幾份? Replica 設幾份? …
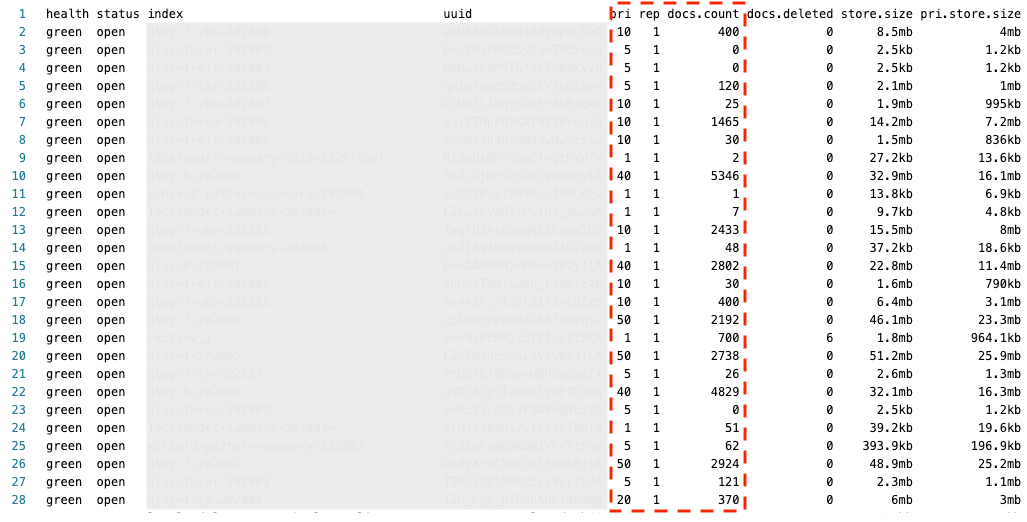
ES Indices Status Example
Shard Size 與 Replica 怎麼決定?
使用 AWS ES 這裡參考的算法是: Number of Shards = Index Size / 30GB
Shard 預設是
5,要注意的是,假設你的 Indices 資料很少建議改成1就好,讓少少的資料集中在同一個 Shard,可以避免讓整體的 ES 資料分布不均,查詢效能低落。
AWS ES 價格不菲,如果 Replica 份數想要愈多佔用 DISK 容量愈大必需要更多台 Node,你可以根據資料的重要程度來設定就是了。
JVM OOM
另外常發生的原因有可能會發生在 JVM Memory,這邊有些建議是:
- 通常發生在 Kibana Query 條件大範圍查詢時,如果 Indices 太肥大很有可能會讓 JVM 飆起來。
- e.g. 原本是以月份切 Indices,可以改由日來切 Indics
- 設定 circuit-breaker 來避免發生 OOM
- JVM 相關的處理也可以參考 AWS Doc 建議 - High-Jvm-Memory-Pressure-Elasticsearch
- 也可以參考小城哥對其他 ES 的深入介紹
Kibana DevTools
以操作介面而言,可以使用 Kibana 的 DevTools 來做 Query 處理,如圖所示使用 HTTP 動詞 + REST URI
Kibana DevTools Query Example
- v: 顯示欄位名稱 -
/_cat/health?v - s: 決定排序欄位及排序方式 -
/_cat/shards?s=state:asc - h: 顯示的 header 欄位